From character image ...
... to editable text
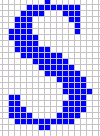
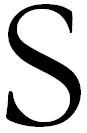
OCR is the process of extracting text from an image. This image can result from scanning a paper document, opening an electronic image file or a PDF file. Images do not have editable text characters, they have many tiny dots (pixels) that together form character shapes. These present a picture of the text on a page.
|
From character image ... |
... to editable text |
|
|
|