通过扫描生成的 PDF 只包含页面图像。Power PDF 使这类只包含图像的 PDF 文档可搜索。该操作可通过光学字符识别 (OCR) 实现。通过校对可使此过程更精确
制作可搜索的 PDF
![]()
单击“主页”>“转换”中的“制作可搜索的 PDF”。
提供“可搜索的 PDF 转换设置”中所述的首选项。
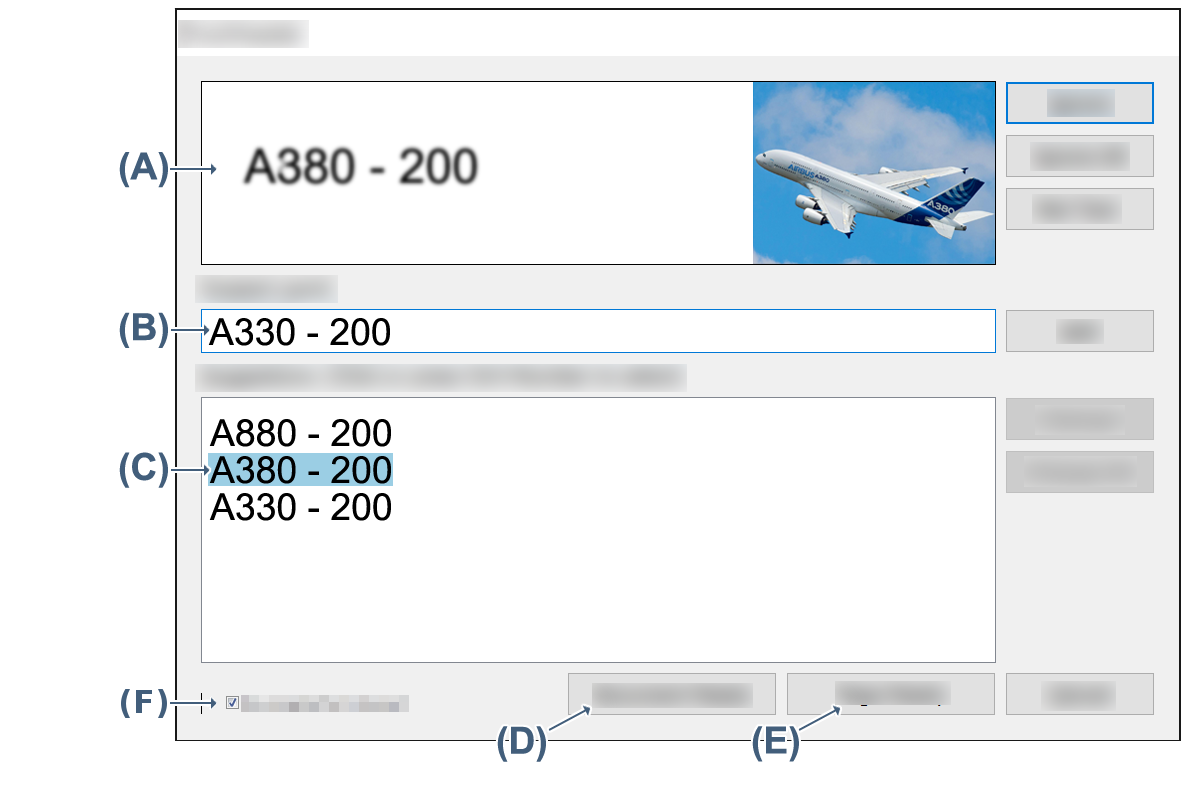
校对可提高 OCR 生成的文本准确度。识别确定每个识别字符和每个字词的置信度。它提供可疑字词以便核对.校对程序面板 (A) 的顶部显示了字词或字符串图。下一个面板 (B) 显示当前解决方案,同时底部面板 (C) 列出了借助字典获得的替代方案。使用右侧按钮保留当前解决方案或选择其中一个建议。如果没有适用项,请在“可疑单词”文本框中键入正确的单词或字符串,然后按“确定”。到达文档结尾之前,单击“文档准备就绪”(D) 按钮以完成校对。单击“页面准备就绪”(E) 可跳过当前页面的其余文本并移动到下一页。选中“在文档中显示可识别的文本”复选框 (F) 可以使文本图层可见,并使原始图像层逐渐消失,在某些情况下,这样可提供更好的可读性。
通过右侧按钮,您可以处理提出的解决方案:
忽略:如果当前建议正确,选择此选项。校对程序将移动到下一个可疑字词。
全部忽略:选择此选项表示接下来所有相同的可疑字词将被视为正确。
非文本:OCR 过程可以为艺术线条或图表创建文本解决方案。使用此按钮放置建议的文本。
添加:接受当前选择的解决方案并将其添加到当前字典
更改:接受当前选择的解决方案。
全部更改:接受当前选择的解决方案并将其添加到接下来所有相同的结果中
如果这些建议均不正确,在编辑框中键入正确的解决方案并单击“更改”或“全部更改”。
当您在“文件”>“选项”>“文档”>“可搜索的 PDF 文档”下制作可搜索的 PDF 时选择运行校对。
在此位置,您可以为 OCR 过程选择一种语言。许多语言支持内置字典功能。可以指定用户词典以补充内置字典或在无内置字典的情况下帮助识别语言。
若无自动校对功能,可在“主页”>“制作可搜索的 PDF”>“校对程序”下请求对特定文件进行自动校对。
也可使用 PDF 创建创建可搜索的 PDF。