Start > Talen, woordenboeken, training > Talen en alfabetten
Het programma ondersteunt meer dan 120 talen en meerdere schriften: Latijns, Grieks, Cyrillisch, Chinees, Japans en Koreaans. Zie de lijst in het deelvenster OCR van het dialoogvenster Opties. Daarnaast vindt u een overzicht op de website van Kofax.
![]()
Dit pictogram geeft een taal aan met woordenboekondersteuning. Op dit moment zijn dit: Catalaans, Deens, Duits, Engels, Esperanto, Fins, Frans, Grieks, Hongaars, Italiaans, Nederlands, Noors, Pools, Portugees, Russisch, Sloveens, Spaans, Tsjechisch en Zweeds. Deze woordenboeken worden samen met gebruikerswoordenboeken en vakwoordenboeken gebruikt bij de herkenningsprocedure en tijdens het proeflezen.
Een overzicht van beschikbare vakwoordenboeken en een toelichting van de opties Eén taal automatisch detecteren en Taalkeuzes controleren vindt u in het deelvenster OCR van het dialoogvenster Opties.
Herkenning via meerdere engines is beschikbaar voor bijna alle woordenboektalen. Elk woordenboek van een actieve herkenningsengine wordt geraadpleegd tijdens de herkenning en suggesties kunnen hieraan worden ontleend.
U heeft de keuze om onbekende woorden, dat wil zeggen woorden die niet in het woordenboek voorkomen te laten onderstrepen in de Teksteditor. Tijdens het proeflezen ziet u deze woorden. Soms worden woorden niet aangegeven, zelfs als ze niet in de woordenboeken voorkomen. Dit gebeurt als meerdere herkenningsengines een identiek resultaat genereren dat naar alle waarschijnlijkheid correct is of als een onbekend woord dat niet in het woordenboek voorkomt vaak verschijnt in een document.
Als u meerdere talen selecteert, worden alle tekens die nodig zijn voor de geselecteerde talen gevalideerd voor herkenning. U kunt tekens ook afzonderlijk valideren, ter aanvulling op de reeds gevalideerde tekens in de gekozen taal.
Als u meer dan één taal met woordenboekondersteuning selecteert, worden alle desbetreffende woordenboeken geraadpleegd, zodat u suggesties in meer dan één taal kunt krijgen.
Voor Japans, Koreaans en Chinees zijn er geen woordenboeken beschikbaar en is proeflezen en trainen niet mogelijk. Combineer deze talen niet met andere. Zie Aziatische talen herkennen.
Dit alfabet wordt gebruikt voor het merendeel van de ondersteunde talen. Als u één of meer talen voor herkenning kiest, worden alle benodigde letters met accenten gevalideerd als aanvaardbare OCR-oplossingen.
Het Griekse alfabet wordt gebruikt voor de Griekse taal. OmniPage ondersteunt herkenning van tekens die nodig zijn voor het lezen van klassiek Grieks. Een klassieke Griekse tekst ziet er als volgt uit:

Een moderne Griekse tekst ziet er als volgt uit:

Hier zijn de ondersteunde tekens:
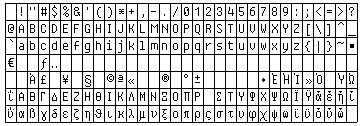
Bij het lezen van Grieks kunnen de letters van het Latijnse alfabet nog steeds worden herkend. U kunt Griekse teksten lezen, bewerken en proeflezen, zelfs als uw computer geen Griekse lettertypebestanden of codetabelondersteuning heeft. Ondersteuning van het Grieks is echter wel noodzakelijk voor het correct exporteren van tekst.
De volgende talen worden geschreven in het Cyrillische alfabet: Russisch, Bulgaars, Wit-Russisch, Tsjetsjeens, Kabardisch, Macedonisch, Moldavisch, Servisch en Oekraïens.
Russische tekst ziet er als volgt uit:

Bij het lezen van Cyrillische talen kunnen de letters van het Latijnse alfabet nog steeds worden herkend. Soms worden letters van het Latijnse alfabet gebruikt midden in Cyrillische teksten. Dit is geen probleem voor OmniPage.
U kunt Cyrillische teksten lezen, bewerken en proeflezen, zelfs als uw computer geen Cyrillische lettertypebestanden of codetabelondersteuning heeft. Ondersteuning van het Cyrillisch is echter wel noodzakelijk voor het correct exporteren van tekst.
De volgende tabel toont welke Cyrillische tekens worden ondersteund. Deze tekens worden niet allemaal gevalideerd voor Russisch of een willekeurige andere taal.

Klik hier voor meer informatie over ondersteuning voor Aziatische talen (Japans, Chinees en Koreaans).