Manual versus Automatic Classification Techniques
Without configuring classification in the Transformation Designer, a person needs to manually classify documents before document processing continues.
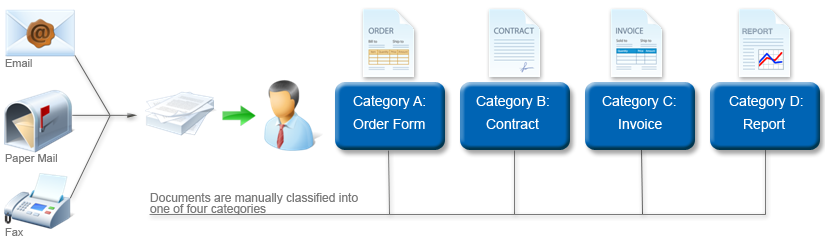
The following example shows a person manually organizing before the documents go to another person or application to continue processing.
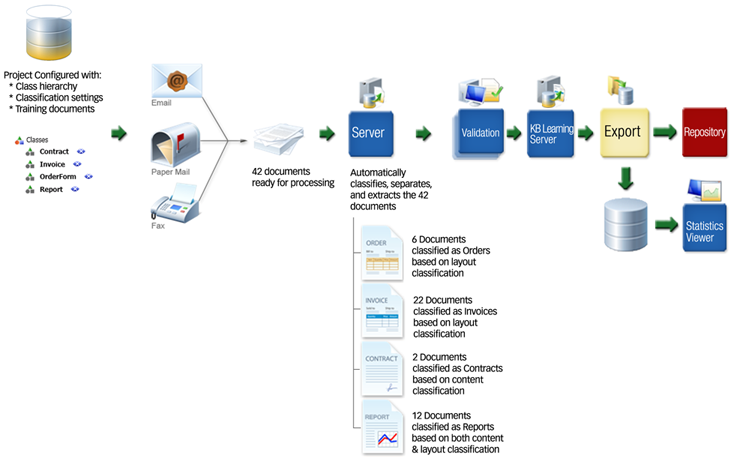
The following example shows how automatic classification removes the manual processing step. Classification is done in a single step along side separation and extraction.
Classification SetThe Layout Classifier and Adaptive Feature Classifier both support learning by example. The first step is to assign sample documents to each class. The classification engines then perform a training process, where all the sample documents are analyzed and the important features are extracted and used to define the classification result for each class. The following steps occur:
-
Definition of categories
-
Creation of a sample set
-
Feature extraction and learning
-
Classification of unknown documents
-
Automatic Improvement and incremental learning
You can now also use Classification Online Learning. If enabled, any document that fails classification and has to be manually classified during Validation is added to the Classification Set. Documents are accumulated as long as the maximum number has not been reached. The next time a document of that class is encountered, its confidence should be higher, and may not need to be manually classified if the Classification Set contains enough example documents.