Tesseract のトレーニング
Kofax RPA は、Tesseract OCR エンジンを使用してテキストを画像からキャプチャーし、インテリジェント スクリーン オートメーション (ISA) を実行します。デフォルトで、Kofax RPA には OCR の言語として英語がインストールされます。言語は、各言語に対応する .traineddata ファイルを提供することで変更が可能です。
特定の言語または文字の認識に問題が発生した場合、Tesseract をトレーニングしてフォントを適切に読み取らせることができます。
トレーニング データの準備用に Kofax RPA で提供されるスクリプトは、Linux オペレーティング システム向けに設計されています。
- 前提条件
-
トレーニング データを作成する前に、システムが以下の前提条件を満たしていることを確認します。
- システムが Ubuntu ベースの場合のシステム要件
-
sudo apt-get install コマンドを使用して以下のライブラリをインストールします。
-
libicu-dev
-
libpango1.0-dev
-
libcairo2-dev
-
git
-
- トレーニングの前提条件
- Kofax RPA インストール ディレクトリ内の nativelib/hub/linux-x64/<hub_id>/tools/tesseract_train/bin に移動して、prepare.sh スクリプトを実行します。例:
$ cd /home/user88/Kapow/nativelib/hub/linux-x64/574/tools/tesseract_train/bin
$ ./prepare.sh
自動トレーニング
このモードは、認識対象の UI で TTF フォント ファイルが使用されている場合に選択します。このモードは、手動トレーニング モードよりもシンプルです。対象のフォント用にトレーニング データを作成するには、tesseract_train/bin フォルダー内の、言語コード、フォント名、フォント ファイル ディレクトリを指定する tesseract_auto.sh スクリプトを以下のように実行します。
$ ./tesstrain_auto.sh --lang eng --fontlist 'Envy Code R' --fonts_dir ..
スクリプトを実行すると、以下のメッセージが表示されます。
Moving /tmp/tmp.OtEqYbS3qV/eng/eng.traineddata to ../output
Completed training for language 'eng'トレーニングしたデータ ファイルを Kofax RPA で使用できるようになります。「オートメーション デバイスの設定」のデフォルトの OCR 言語の変更と、ツリー モードにあるトピックインテリジェント スクリーン オートメーションの「UI 認識言語の変更または追加」を参照してください。
手動トレーニング
このモードは、UI で TTF フォント ファイルが使用されていない場合 (つまり自動モードを適用できない場合) で、ロボットの認識対象となる文字がすべてアルファベットの UI スクリーン ショットが多数ある場合に選択します。トレーニング画像ファイルがスクリプトによって自動的に作成される自動モードとは異なり、トレーニング画像は手動で作成する必要があります。このファイルの作成には、時間と労力が必要になります。
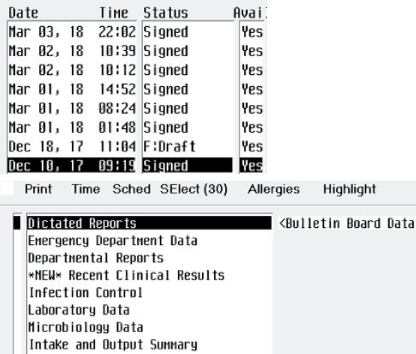
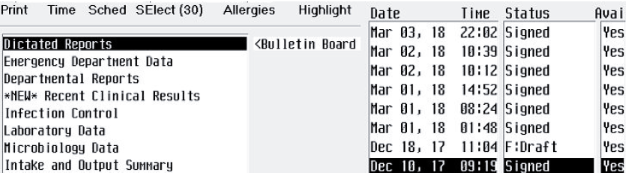
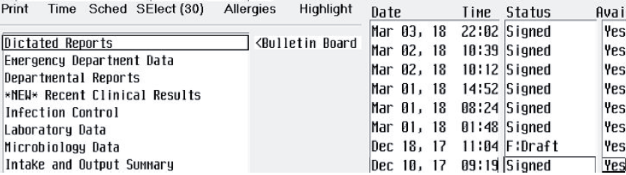
Tesseract 用のトレーニング データ ファイルを作成するには、以下の手順を実行します。ファイルには、最終トレーニング データ ファイルに必要なすべての文字 (大文字および小文字、数字、コンマ、ピリオドなど) を含む必要があります。以下の例は、次の UI で使用するトレーニング データの作成方法を示しています。
-
使用する完全な文字セットを決定します。トレーニング ファイルの作成時には、各文字に対するサンプルの最小数は 5 であることに注意してください。最も頻繁に使用される文字の場合、追加でサンプルを含めます。
-
単一の TIFF ファイルに、トレーニングで使用する UI スクリーン ショットの全部分を貼り付けます。この操作では使用する画像エディターは任意です。この例では、ターゲットのアルファベットを 10 ~ 15 の英字に限定します。実際の操作では、すべての文字のサンプルを用意します。
-
反転色の領域を選択して、色を反転させて通常色にします。
-
大文字の高さが 36 ピクセルになるように、キュービック補間を使用して画像の大きさを調節します。この例では、画像の大きさを 2.97 倍に拡大しました (画像の一部のみを表示)。
-
単語を調節して、テキスト領域間に大きな空白がなくてもテキスト行を容易に検出できるようにします。以下の例のように、余分と思われるテキストを除去します (ページに合わせて縮小しています)。
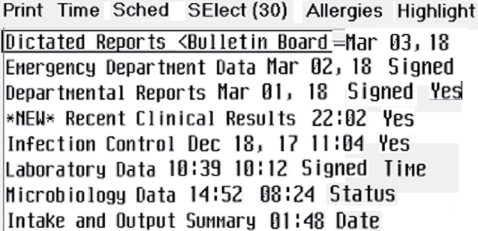
-
画像をグレースケールに変換し、テキストの質が最も良くなるしきい値の色効果を適用します。適切なしきい値を選択することは難しい可能性があります。複数の異なるしきい値を適用することを考慮し、結果の画像を単一の TIFF ファイルにコピーします。トレーニング画像に、表現の異なる同じ文字が複数含まれることになります。この例では GIMP エディターで 125 および 150 のしきい値を適用して、画像を 1 つのファイルにコピーしました。画像の上にある文字のほうが、下にある文字よりも薄いことが分かります (ページに合わせて縮小しています)。
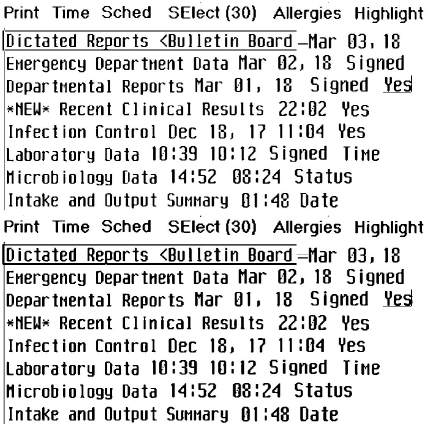
-
以下の例のように、手動でノイズを除去します (ページに合わせて縮小しています)。
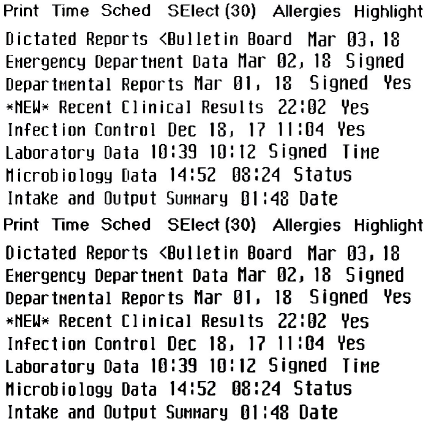
-
画像を圧縮せずに TIF または TIFF 形式で MyFont.tif のような名前で保存します。
-
ボックス ファイルを作成します。ボックス ファイルは、画像を囲む境界ボックスの座標を使用して、トレーニング画像内の文字を 1 行ごとに 1 文字ずつリストするテキスト ファイルです。GitHub には、Tesseract プロジェクトでボックス ファイルを作成する際に使用できるツールがいくつかあります:https://github.com。
非常に有用な方法の 1 つに、Tesseract OCR Chopper オンライン ツールがあります。このオンライン ツールを使用してボックス ファイルを作成するには、以下の手順を実行します。
-
Tesseract OCR Chopper ページに移動します。
-
作成した TIF ファイルをアップロードします。
-
文字を選択し、適切に認識されていることを確認します。認識されていない場合は、画像のフォームの下にあるフィールドで文字の値を変更します。
この操作を画像内のすべての文字に対して実行します。
-
ボックスのテキストをコピーし、新規ファイルに貼り付けて MyFont.box のような名前にします。
この例では、ボックス ファイルは以下の行から開始します。
P 15 1076 39 1108 0 r 41 1076 53 1100 0 i 57 1076 62 1108 0 n 68 1076 89 1100 0 t 92 1076 ... -
-
tesseract_train/bin フォルダーに移動し、言語コード、TIF ファイルとボックス ファイルへのパスを指定する tesstrain_manual.sh スクリプトを以下のように実行します。
$ ./tesstrain_manual.sh --lang eng --box_file ../MyFont.box --training_image ../MyFont.tif
スクリプトを実行すると、以下のメッセージが表示されます。
Moving /tmp/tmp.OtEqYbS3qV/eng/eng.traineddata to ../output
トレーニングしたデータ ファイルを Kofax RPA で使用できるようになります。「オートメーション デバイスの設定」のデフォルトの OCR 言語の変更と、ツリー モードにあるトピックインテリジェント スクリーン オートメーションの「UI 認識言語の変更または追加」を参照してください。
詳細については、GitHub Web サイトの Tesseract wiki ページを参照してください。