回帰分析
回帰分析が実行されると、[係数] 列と[p 値]列はページの下部に表示される結果と指標式が読み込まれます.
各項の p 値は、係数がゼロに等しい (効果なし) という帰無仮説をテストします。低い p 値 (<0.05) は、帰無仮説を棄却できることを示します。言い換えれば、p 値が低い予測変数は、予測変数の値の変化が応答変数の変化に関連するため、回帰分析に意味のある追加になる可能性があります。
逆に、より大きな (有意ではない) p 値は、予測変数の変化が応答の変化に関連していないことを示しています。0.05 を超える p 値は赤で表示されます。
次の線形回帰式が使用されます。 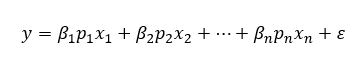
条件:
- y: 予測されるターゲット指標
-
ß i: 回帰係数 (因子)
-
p i: Insight パラメーター
-
x i: ソース指標値
-
Ɛ: 自由係数
結果を分析し、分析から除外する指標を決定し、それらをリストから削除 (または新しい指標を追加) して、必要な回数だけ分析を実行できます。必要に応じて、係数を手動で変更することもできます。
[分析結果] タブを使用して、回帰モデルの係数を確認します。
R は、Y の予測値と観測値の間の相関です。
R 2 は、回帰モデルを使用して回帰指標をどれだけうまく予測できるかを示す指標です。一般に、R 2値が高いほど、モデルはデータによりよく適合します。
F はフィッシャー統計の値です。
有意性 F は、方程式が y の変動を説明しない確率、または純粋に偶然の近似である確率を示しています。これは、F 確率分布に基づいています。有意性 F が 0.1 (10%) 以上の場合、意味のある相関関係はありません。
観測値は、分析されたデータの量です。
自由係数の p 値は、モデルの品質を推定するために使用されます。