Apprentissage Tesseract
Kofax RPA utilise le moteur OCR Tesseract ou OmniPage pour capturer du texte à partir d'images et pour exécuter une automatisation d'écran intelligente (ISA). OmniPage inclut toutes les langues prises en charge dans l'installation. Pour Tesseract, seule la langue anglaise est incluse dans l'installation. Vous pouvez changer la langue dans Tesseract en fournissant un fichier .traineddata pour la langue correspondante.
Si vous rencontrez des problèmes pour reconnaître des langues ou des lettres spécifiques, vous pouvez entraîner Tesseract à lire correctement les polices.
Les scripts fournis par Kofax RPA pour la préparation des données d'apprentissage sont destinés aux systèmes d'exploitation Linux. Actuellement, la version 3.4.0 de Tesseract est utilisée.
- Conditions préalables
-
Assurez-vous que votre système est conforme aux conditions préalables suivantes avant de créer des données d'apprentissage.
- Conditions requises pour les systèmes à base d'Ubuntu
-
Installez les bibliothèques suivantes à l'aide de la commande sudo apt-get install comme suit.
sudo apt-get install libicu-dev libpango1.0-dev libcairo2-dev git
- Prérequis d'apprentissage
- Accédez à nativelib/hub/linux-x64/<hub_id>/tools/tesseract_train/bin dans le répertoire d'installation Kofax RPA et exécutez le script prepare.sh. Par exemple :
$ cd /home/user88/Kofax_RPA/nativelib/hub/linux-x64/574/tools/tesseract_train/bin
$ ./prepare.sh
Apprentissage automatique
Choisissez ce mode si vous avez le fichier de police TTF utilisé dans l'interface utilisateur que vous souhaitez reconnaître. Ce mode est plus simple que le mode d'entraînement manuel. Pour créer un fichier de données d'apprentissage pour la police souhaitée, exécutez le script tesseract_auto.sh situé dans le dossier tesseract_train/bin en spécifiant le code de langue, le nom de la police et le répertoire du fichier de police comme suit.
Assurez-vous d'exécuter le script depuis le répertoire de travail tesseract_train/bin.
$ ./tesstrain_auto.sh --lang eng --fontlist 'Envy Code R' --fonts_dir ..
Après l'exécution du script, le message suivant devrait s'afficher.
Moving /tmp/tmp.OtEqYbS3qV/eng/eng.traineddata to ../output
Completed training for language 'eng'Vous pouvez maintenant utiliser le fichier des données apprises dans Kofax RPA. Voir Modifier la langue OCR par défaut dans Configurer le dispositif d'automatisation et « Modifier ou ajouter une langue de reconnaissance de l'interface utilisateur » sous la rubrique Automatisation d'écran intelligente dans Modes arborescence.
Apprentissage manuel
Choisissez ce mode si vous n'avez pas le fichier de police TTF utilisé dans l'interface utilisateur (le mode Automatique ne peut donc pas être appliqué), mais que vous avez de nombreuses captures d'écran de l'interface utilisateur qui incluent tous les caractères alphabétiques que le robot doit reconnaître. Contrairement au mode automatique, où un fichier d'image d'apprentissage est créé automatiquement par le script, vous devez créer manuellement une image d'apprentissage. Il faut du temps et de l'assiduité pour créer un tel fichier.
Procédez comme suit pour créer un fichier de données d'apprentissage pour Tesseract. Le fichier doit contenir tous les caractères (lettres majuscules et minuscules, chiffres, signes de ponctuation, etc.) qui doivent être présents dans le fichier final des données d'apprentissage. L'exemple partiel ci-dessous montre comment créer des données d'apprentissage à utiliser avec l'interface utilisateur suivante.
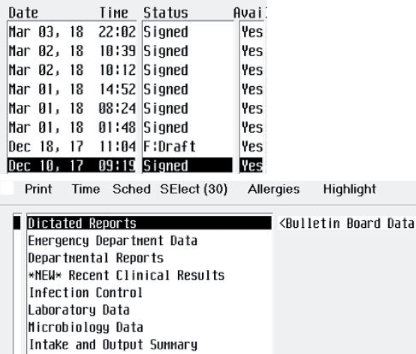
-
Déterminez le jeu de caractères complet à utiliser. Gardez à l'esprit lors de la création d'un fichier d'apprentissage que le nombre minimal d'échantillons pour chaque caractère est de cinq. Pour les caractères les plus fréquemment utilisés, insérez des échantillons supplémentaires.
-
Placez toutes les parties des captures d'écran de l'interface utilisateur qui seront utilisées pour l'apprentissage dans un seul fichier TIFF. Vous pouvez utiliser n'importe quel éditeur d'image pour cette opération. Dans cet exemple, nous limitons l'alphabet cible à 10-15 lettres anglaises. En production, assurez-vous d'avoir des exemples de toutes les lettres.
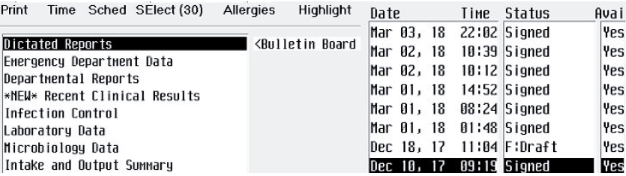
-
Sélectionnez les zones avec des couleurs inversées et restaurez-les à la normale.

-
Mettez l'image à l'échelle à l'aide d'une interpolation cubique de sorte que les lettres majuscules aient une hauteur égale à 36 pixels. Pour cet exemple particulier, nous avons agrandi l'image 2,97 fois (en ne montrant qu'une partie de l'image).
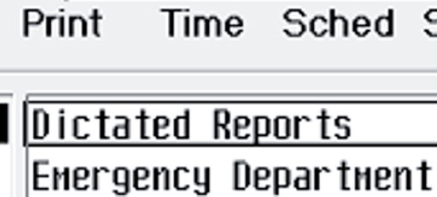
-
Réorganisez les mots pour avoir des lignes de texte facilement détectables sans grands espaces entre les zones de texte. Supprimez le texte qui est redondant à votre avis, comme dans l'exemple suivant (réduit pour s'adapter à la page).
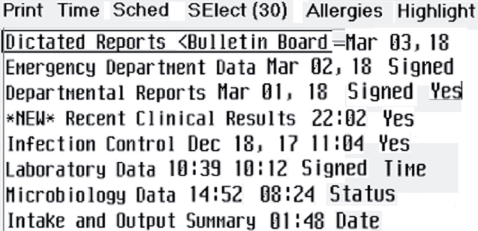
-
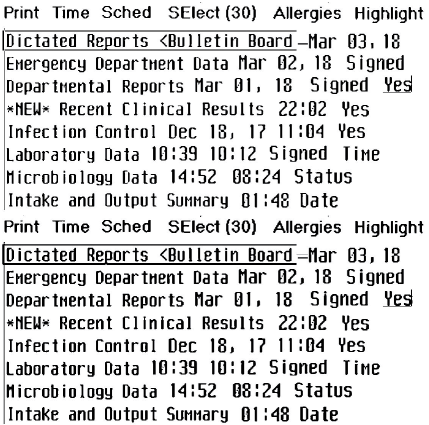
Convertissez l'image en niveaux de gris et appliquez un effet de couleur de seuil qui produit un texte de meilleure qualité. Il peut être difficile de sélectionner le seuil approprié. Envisagez d'appliquer au moins deux seuils différents et copiez les images résultantes dans un seul fichier TIFF. L'image d'apprentissage contiendra de nombreuses représentations différentes de la même lettre. Dans cet exemple, nous avons appliqué les seuils 125 et 150 dans l'éditeur GIMP et copié les images dans un seul fichier. Vous remarquerez peut-être que le texte dans la moitié supérieure de l'image est plus fin que dans la moitié inférieure (réduit pour s'adapter à la page).
-
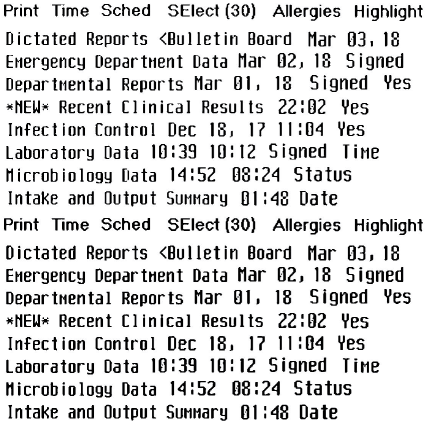
Supprimez manuellement le bruit comme dans l'exemple suivant (réduit pour s'adapter à la page).
-
Enregistrez l'image au format TIF ou TIFF sans compression, tel que MaPolice.tif.
-
Créez un fichier boîte. Le fichier boîte est un fichier texte qui répertorie les caractères de l'image d'apprentissage, un par ligne, avec les coordonnées du cadre de sélection autour de l'image. Voir la page « Training Tesseract - Make Box Files » (Apprentissage Tesseract – Créer des fichiers boîte) dans le projet Tesseract sur GitHub : https://github.com.
Copiez le texte de la boîte et placez-le dans un nouveau fichier, tel que MaPolice.box.
Dans notre exemple, le fichier boîte doit commencer par les lignes suivantes :
P 15 1076 39 1108 0 r 41 1076 53 1100 0 i 57 1076 62 1108 0 n 68 1076 89 1100 0 t 92 1076 ... -
Accédez au dossier tesseract_train/bin et exécutez le script tesstrain_manual.sh, en spécifiant le code de langue et les chemins d'accès à l'image TIF et au fichier boîte, par exemple :
$ ./tesstrain_manual.sh --lang eng --box_file ../MaPolice.box --training_image ../MaPolice.tif
Après l'exécution du script, le message suivant devrait s'afficher.
Moving /tmp/tmp.OtEqYbS3qV/eng/eng.traineddata to ../output
Vous pouvez maintenant utiliser le fichier des données apprises dans Kofax RPA. Voir Modifier la langue OCR par défaut dans Configurer le dispositif d'automatisation et « Modifier ou ajouter une langue de reconnaissance de l'interface utilisateur » sous la rubrique Automatisation d'écran intelligente dans Modes arborescence.
Plus d'informations sont disponibles sur les pages wiki de Tesseract sur le site web GitHub.